Once upon a time, I asked a colleague for their dataset featured in a published article. The article produced a significant correlation between two variables, and I wanted to reproduce the findings using their dataset. Lo and behold, I was able to successfully replicate the correlation! However, when I further inspected their data, I noticed a particular concern. It seemed that the significance of the relationship hinged on a single value that could be considered an outlier. I struggled with whether I should bring this up to my colleague, but I finally did after much thought. Their response educated me on outliers, but it also exposed me to a new type of Statistical Bullshit – and how reasonable statistical practices could be confused for Statistical Bullshit.
Today’s post first discusses Statistical Bullshit surrounding outliers. Then, I summarize the discussion that I had with my colleague, and why things don’t always seem as they appear when it comes to outliers and Statistical Bullshit!
While many different types of outliers can be classified, today’s post discusses three. The first uses the following dataset: Click Here for Dataset . In this dataset, we have job satisfaction and job performance recorded for 29 employees. Each scale ranges from 0 to 100. When we calculate a correlation between these two variables, we get a perfect and statistically significant relationship (r = 1.00, p < .01). But let’s look at a scatterplot of this data.
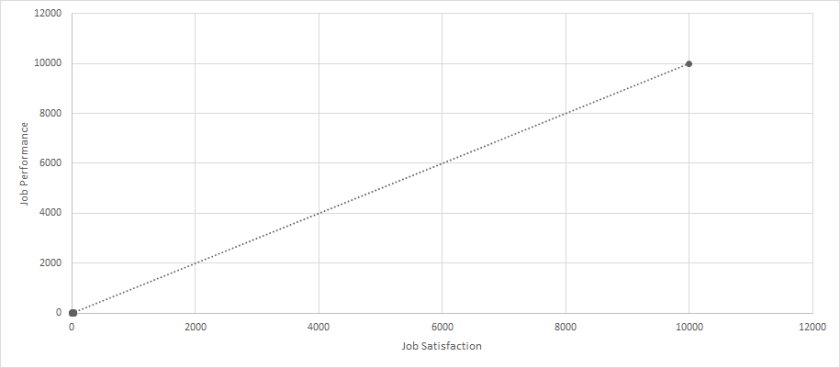
Hmm, clearly something is wrong! This is because one employee had missing data for both variables, and the missing data was coded as 9999; however, when the analyses were performed, the 9999 was not properly removed and/or the program was not told that 9999 represented missing data. When we run the analyses again with the outlier removed, the correlation is small and not statistically significant (r = .08, p > .05).
I label this type of outlier as a researcher error outlier. Numerically it is an outlier, but it does not represent actual data. In all cases, this outlier should certainly be removed.
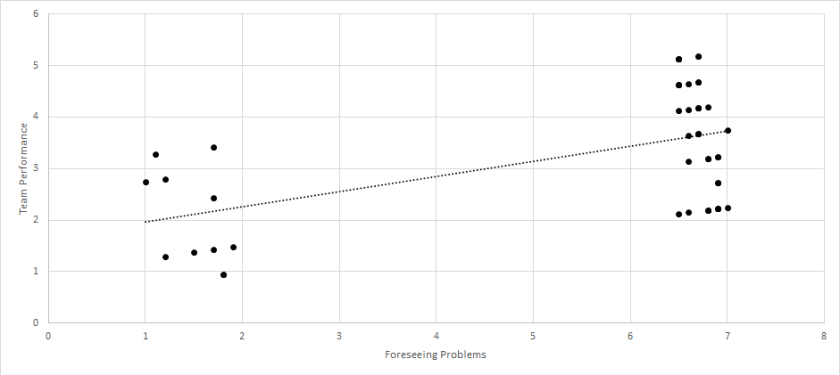
Next, let’s use the following dataset to discuss a second type of outlier: Click Here for Dataset. Again, we have job satisfaction and job performance recorded for 29 employees. Each scale ranges from 0 to 100. When we calculate a correlation between these two variables, we get a very strong and statistically significant relationship (r = .76, p < .01). But let’s look at a scatterplot of this data.
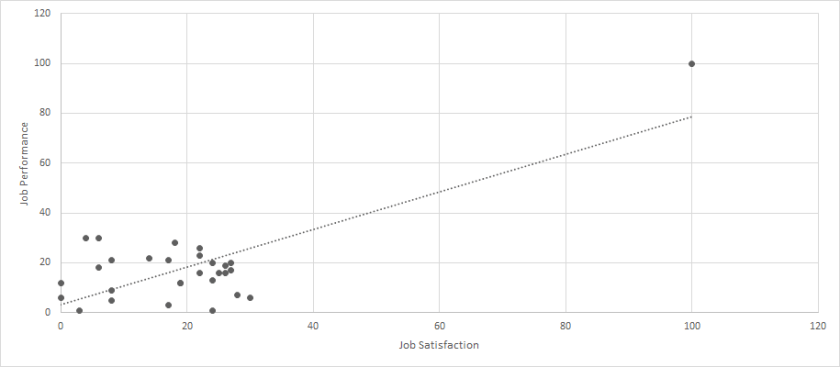
Interesting. We certainly have an outlier, but it is not clearly “wrong.” Instead, it seems that most of the sample falls within the range of 0-30 for each variable, but one person had a value of 100 for both. When we run the analyses again with the outlier removed, the correlation is small and not statistically significant (r = .01, p > .05).
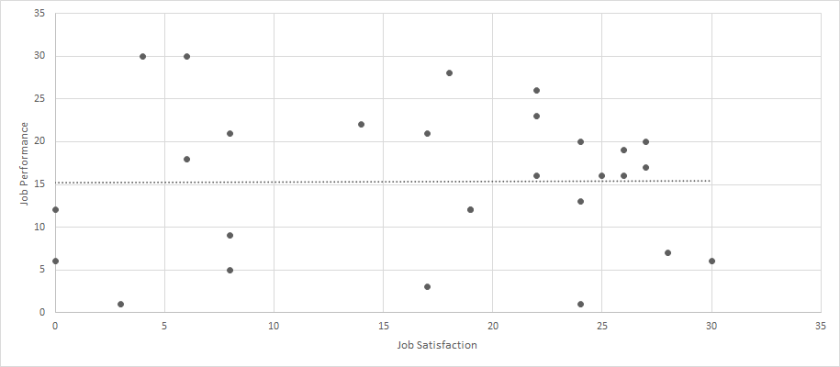
But, before being satisfied with our removal, we should strongly consider what this means for our data. The occurrence of the one person certainly throws off our results, but this one person does indeed represent actual, meaningful data. So, can we justify removing this person? This question can be partially answered by determining whether we are interested in all employees or typical employees. If we are interested in all employees, then the outlier should certainly stay in the dataset. If we are interested in typical employees, then the outliers should possibly be removed. No matter the decision, however, researchers and practitioners should report all of their analytical decisions, so that any readers could be aware of changes to the data before further analyses were conducted.
I label this type of outlier as an extreme outlier.
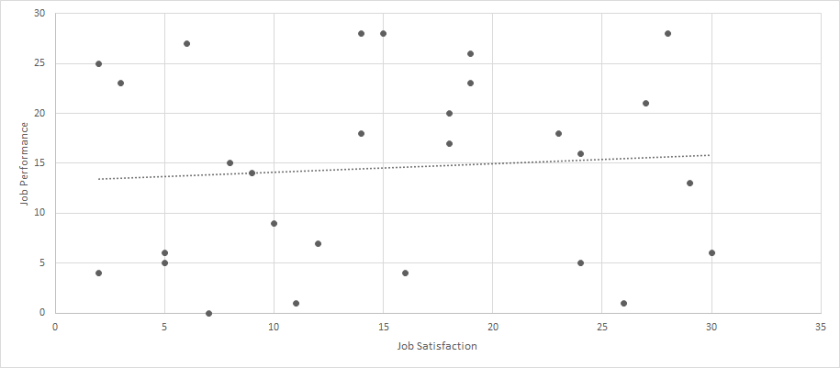
Lastly, let’s use the following dataset to discuss a third type of outlier: Click Here for Dataset. Again, we have job satisfaction and job performance recorded for 29 employees. Each scale ranges from 0 to 100. When we calculate a correlation between these two variables, we get a moderate and statistically significant relationship (r = .32, p < .01). But let’s look at a scatterplot of this data.
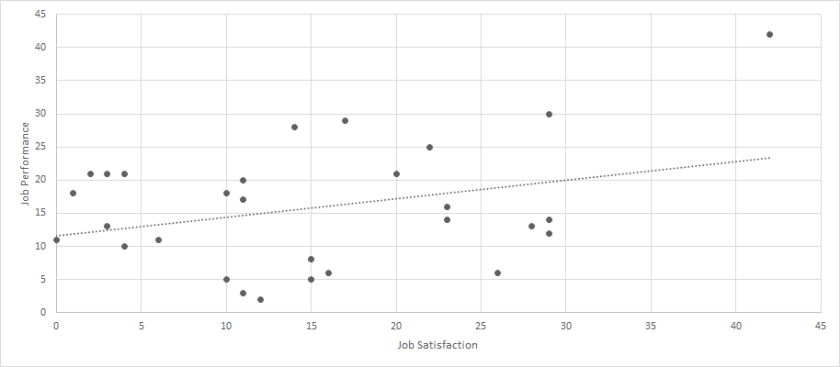
Now, we certainly have an outlier, but it is much closer to the other values. While most of the sample falls within the range of 0-30 for each variable, but one person had a value of 43 for both. When we run the analyses again with the outlier removed, the correlation is small and not statistically significant (r = .07, p > .05).
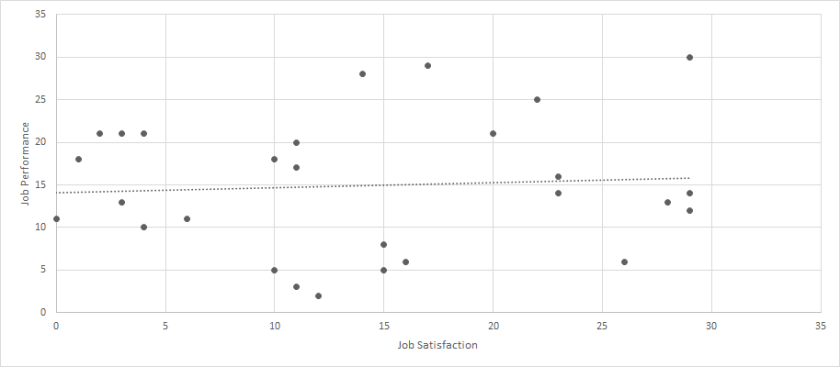
Like the prior case, we need to strongly consider whether we should remove this participant. It would be much more difficult to argue that this person represents unreasonable data, and it may even be difficult to argue that this person represents data that deviates from the typical population. Yes, the person is a little extreme, but they are not drastically different. For this reason, it is likely that we want to keep this observation within our sample. I label this type of outlier as a reasonable outlier.
So, how is this relevant to Statistical Bullshit? Well, for researcher error outliers, the entire significance of a relationship could be built on a single mistake. Large decisions could be made based on nothing factual at all. Similarly, for extreme outliers, our relationship could largely be driven by a single person, and our decisions could be overly influenced by this single person. Lastly, for reasonable outliers and some extreme outliers, we could choose to remove these observations, which could result in a very different relationship that we could base our decisions. However, our decisions would be based on only a portion of the sample, and we could be missing out on very important aspects of the population. Thus, both not removing and removing outliers could result in Statistical Bullshit!
To bring this post full-circle, what happened when I chatted with my colleague? As you probably guessed, the outlier was determined to be a reasonable outlier. Certainly an outlier, but not enough to be confidently considered outside the typical population range. After our conversation, I certainly saw their point, and felt that they made the correct decision with their analyses – and it helped me understand how to conduct my analyses in the future.
Well, that’s all for today! If you have any questions, comments, or stories, please email me at MHoward@SouthAlabama.edu. Until next time, watch out for Statistical Bullshit!