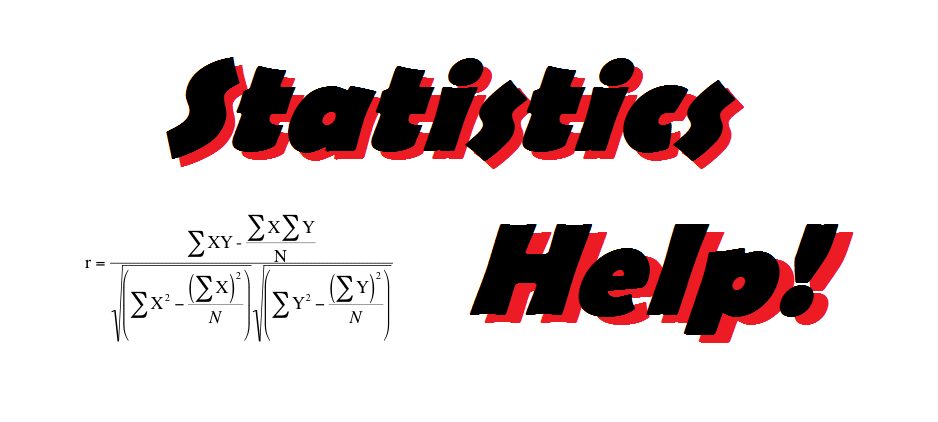I have still shifted my gears to creating statistics help pages. After making pages for Excel, SPSS, R, and Jamovi, it is only natural that I start making pages for Python. These guides are hosted on MattCHoward.com, and you can access them at the following link: https://mattchoward.com/python-statistics-help/. Below are links to the first three guides:
Downloading Python for Windows
Installing Python Modules
Opening .csv File in Python
Please let me know if you have any questions, comments, or requests regarding Python by emailing me at MHoward@SouthAlabama.edu. I can’t guarenttee that I can help. . .but you can still email me!