Need help with performing statistics in R? Two new pages have been added to MattCHoward.com on the topic. If you have a particular analysis that you need help with, feel free to email MHoward@SouthAlabama.edu with questions or comments!
Tag: Methodology
Rules of Probability
It’s a new semester! That means that I’ll be updating my websites a little more often. The first update is to the Statistics Help section of MattCHoward.com, in which I go over the basic rules of probability. It can be found here: Rules of Probability. If you have any questions or content that you’d like to see, please email me at MHoward@SouthAlabama.edu.
Correlation Does NOT Equal Causation
Your variables may be related, but does one really cause the other?

Most readers have probably heard the phrase, “correlation does not equal causation.” Recently, however, I heard someone confess that they’ve always pretended to know the significance of this phrase, but they truly didn’t know what it meant. So, I thought that it’d be a good idea to make a post on the meaning behind “correlation ≠ causation.”
Imagine that you are the president of your own company. You notice one day that your highly-payed employees perform much better than your lower-payed employees. To test whether this is true, you create a database that includes employee salaries and their performance ratings. What do you find? There is a strong correlation between employee pay and their performance ratings. Success! Based on this information, you decide to improve your employees’ performance by increasing their pay. You’re certain that this will improve their performance. . .right?
Not so fast. While there is a correlation between pay and performance, there may not be a causal relationship between the two – or, at least, such that pay directly influences performance. It is fully possible that increasing pay has little effect on performance. But why is there a correlation? Well, it is also possible that employees get raises due to their prior performance, as the organization has to provide benefits in order to keep good employees. Because of this, an employee’s high performance may not be due to their salary, but rather their salary is due to their prior high performance. This results in current performance and pay having a strong correlational relationship, but not a causal relationship such that pay predicts performance. In other words, current performance and pay may be correlated because they have a common antecedent (past performance).
This is the idea behind the phrase, “correlation does not equal causation.” Variables do not necessarily have a causal relationship just because they are correlated. Instead, many other types of underlying relationships could exist, such as both having a common antecedent.
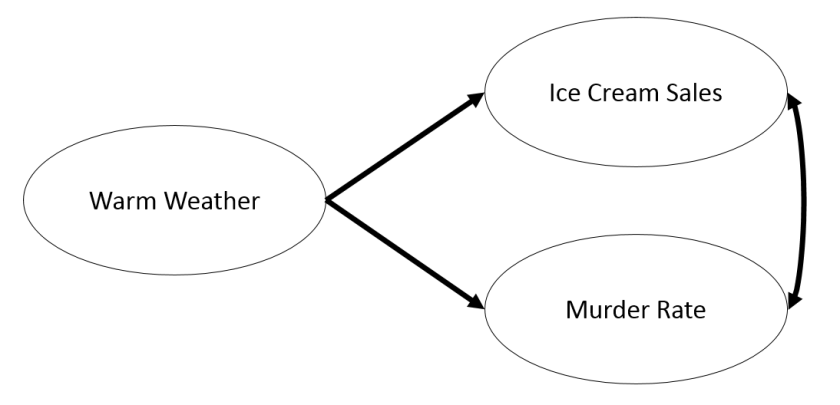
Still don’t quite get it? Let’s use a different example. Prior research has shown that ice-cream sales and murder rates are strongly correlated, but does that mean that ice cream causes people to murder each other? Hopefully not. Instead, it is that warm weather (i.e. the summer) causes people to (a) buy ice cream (b) and be more aggressive. This results in both ice-cream sales and murder rates. Once again, these two variables are correlated because they have a common antecedent – not because there is a causal relationship between the two.
Hopefully you now understand why correlation does not equal causation. If you don’t, please check out one of my favorite websites: Spurious Correlations. This website is a collection of very significant correlations that almost assuredly do not have a causal relationship – thereby providing repeated examples of why correlation does not equal causation. If you do understand, beware of this fallacy in the future! Organizations can make disastrous decisions based on falsely assuming causality. Make sure that you are not one of these organizations!
Until next time, watch out for Statistical Bullshit! And email me at MHoward@SouthAlabama.edu with any questions, comments, or stories. I’d love to include your content on the website!
