Accurate measurement of variables is essential for business success. Sometimes, it’s fairly easy to record these variables – sales, revenue, profit. Other times, it can be very very difficult. For example, let’s say that you want to hire employees that are smart and conscientious. How can we measure intelligence and conscientiousness?
Well, a good starting point is to develop a test or survey. Many intelligence tests exist with varying levels of sophistication and accuracy, and you could pay to give these tests to applicants. Many self-report surveys also exist that can measure conscientiousness, and you could pay to give these tests to applicants, too. But what if you don’t want to use one of these existing measures? What’s the worst that could happen?
In this post, we won’t talk about the worst that could happen, but we’ll discuss a pretty bad outcome: when your measure inadvertently gauges the wrong construct, which could result in a lawsuit.
I should also note that this example comes from an actual consulting experience that I encountered. The names have been changed, but remember that these things actually happen in industry!
I was once hired along with a full team to review the new selection system of a trendy company. Let’s call them X-Corp. X-Corp wanted their selection to measure a construct that they invented: “the ideal X-Corp employee.” They made a list of the ideal X-Corp employee characteristics. It included the common constructs like intelligence and conscientiousness, but it also included some unorthodox constructs. These included hip, stylish, savvy, sleek and so fourth. X-Corp argued that the ideal employee needed to appeal to any potential customers, and therefore needed to have these characteristics; however, my team was already doubtful about the business relevance of theses constructs.
Even more concerning, X-Corp felt that their survey had to attract people to work for X-Corp. For this reason, it couldn’t be a traditional survey. It had to be different and exciting. Once again, we were doubtful about how exciting a selection survey could be.
When we saw the survey to measure “the ideal X-Corp employee,” we began to worry even more. The first question looked something like this:
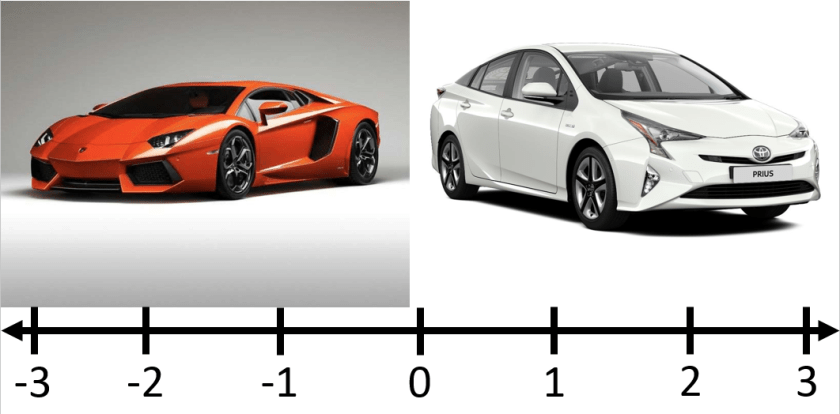
What?
The text of the item read, “Using the scale, please indicate whether you are more like a sports car or a hybrid/electric car.”
…What?
Immediately, we asked X-Corp what this item was meant to measure. Sure enough, they just said “the ideal X-Corp employee.” We asked which subdimension, specifically, was the item meant to measure. As they couldn’t respond, we realized that they didn’t really have an idea. It seemed that they just put things in their survey that they thought would be a good idea without really thinking about the ramifications.
Do you think this item would help identify good employees? Well, we first have to ask what is the “correct” answer. According to X-Corp, the correct answer was being more like a hybrid/electric car. So, anyone would indicated that they were more like a sports car got the item wrong. Do you think this is fair? More importantly, do you think those that feel more like a “hybrid/electric car” are necessarily better than those that feel more like a “sports car?” I would guess that the answer is probably not. There are probably many sports car people that are more intelligent, conscientious, hip, savvy, and so on when compared to hybrid/electric car people. Thus, this item probably fails to measure “the ideal X-Corp employee.”
That item was bad, but it wasn’t the worst. The worst was probably the following item:
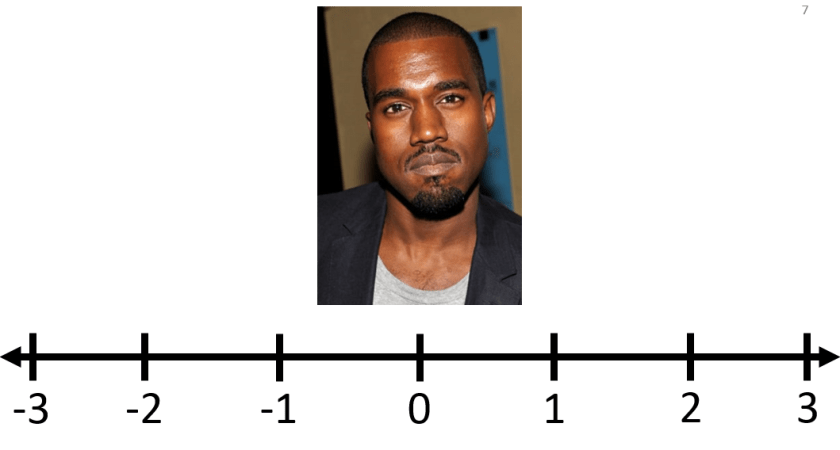
Once again, what?
The text of the item read, “Using the scale, please indicate whether you are more or less like Kanye West.”
Once again…what?
X-Corp claimed that Kanye West was too narcissistic, and anyone who felt that they were like Kanye were not welcome at X-Corp. Do you think that Kanye people are inherently worse than non-Kanye people? Once again, I am guessing that the answer is probably not. Kanye people are probably just as good as non-Kanye people, and perhaps even better in some regards (i.e. creative, hip, etc.). But can you think of anything else that this item might inadvertently measure? Let’s look at the graph below, which is similar to the actual results.
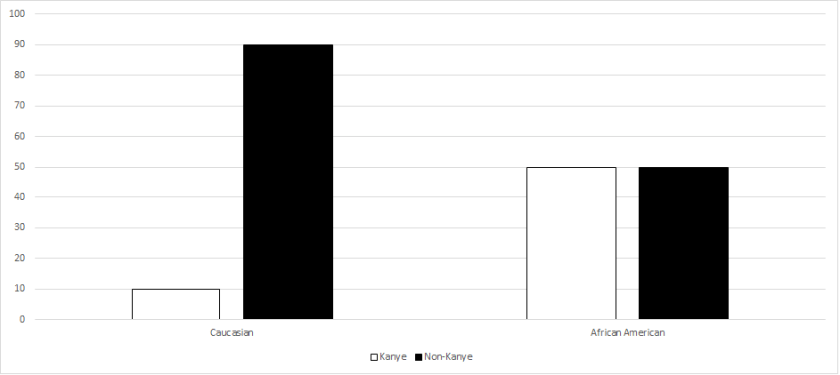
As some of you may have guessed, African Americans were much more likely to see themselves similar to Kanye than Caucasians. This makes sense, as Kanye himself is African American. Thus, this item partially measures the applicant’s ethnicity.
Remember when I said that those responding that they were more like Kanye were rated as worse applicants? If this survey went live, that would mean that African Americans would automatically be penalized, thereby resulting in adverse impact. This would almost assuredly result in a lawsuit, in which X-Corp could not justifiably defend – or, at least, have a very hard time defending that the Kanye question actually represented job performance. This would have cost the company millions of dollars!
In the end, my team strongly recommended that the company should not use their selection survey, and should instead use a traditional survey. The company wasn’t happy, and we were never asked to work with the company again. But, they did guarantee that they would not use their selection system. While it wasn’t the most satisfying result, I was happy that we were able to stop another case of Statistical Bullshit!
If you have any questions or comments about this story, feel free to contact me at MHoward@SouthAlabama.edu . Also, feel free to contact me if you have any Statistical Bullshit stories of your own. I’d love to include them on StatisticalBullshit.com!